https://arxiv.org/abs/1706.09138
Conference on Computer Vision and Pattern Recognition (CVPR), 2017
1. Introduction
Image-to-Image Transformation -> Input 이미지를 원하는 output 이미지로 출력하는 것을 목표로 한다.
선행연구에서는 Image-to-Image transformation을 수행하기 위해서, CNN을 supervised manner로 학습시켜왔다.
이는 Input 이미지를 hidden representation으로 인코딩을 하고, output 이미지로 디코딩을 하는 방식이다.
또한, 선행연구는 GAN을 사용하여 Image-to-Image Transformation을 수행하기도 하였다.
이 논문은 GAN에서 영감을 받은 PAN (Perceptual Adversarial Networks)을 소개한다. PAN은 image transformation network T와 discriminative network D로 구성되어 있다.
Generative Adversarial Loss와 Perceptual Adversarial Loss 모두 구현되어 있다.
이 논문이 만든 주요 contribution은 다음과 같다.
1. Perceptual Adversarial Loss를 제안함. Perceptual Adversarial Loss는 Discriminative network의 숨겨진 layer들을 사용하고, Adversarial 학습 과정을 통해서 output과 ground-truth 이미지의 차이를 계산하는 방식이다.
2. Perceptual Adversarial Loss와 Generative Adversarial Loss를 합쳐서 PAN을 제시함.
3. PAN의 성능을 image-to-image transformation 과제에 적용하여 검증하였다.
2. Background
선행된 Image-to-Image Transformation에 대해서 소개하고 있다.
Image-to-Image Transformation이 처음 다루어보는 소재이기에 간략하게 정리하였다.
A. Image-to-Image Transformation with feed-forward CNNs
Feed-forward CNN은 back-propagation 알고리즘을 이용하여 손쉽게 학습시킬 수 있다. 이미지 transformation은 input 이미지를 CNN에 통과시키는 형식으로 진행이 된다.
**추가 필요!!!!!
3. Methods
먼저, Generative Adversarial Loss와 Percepual Adversarial Loss에 대해서 소개한다.
A. Generative Adversarial Loss
일단 논문은 Vanilla GAN의 Generative Adversarial Loss에 대한 설명부터 시작한다.
Generative Network G는 noise distribution pz에서 real-world data distribution pdata로 샘플링하도록 학습이 되어진다.
학습 과정에서 Discriminitive network D는 실제 샘플 (pdata)와 생성된 샘플 G(z)를 구분하는 것을 목표로 한다.
반대로, Generative Network G는 굉장히 사실적인 샘플을 생성하여서 Discriminitive network D를 헷갈리게 만들려고 노력을 한다. 이러한 과정을 Minimax Game이라고 부르고, 이에 대한 수식은 다음과 같다.

이 논문에서는 Image-to-Image Transformation 과제 수행을 위해서 GAN의 학습 방법을 사용한다.
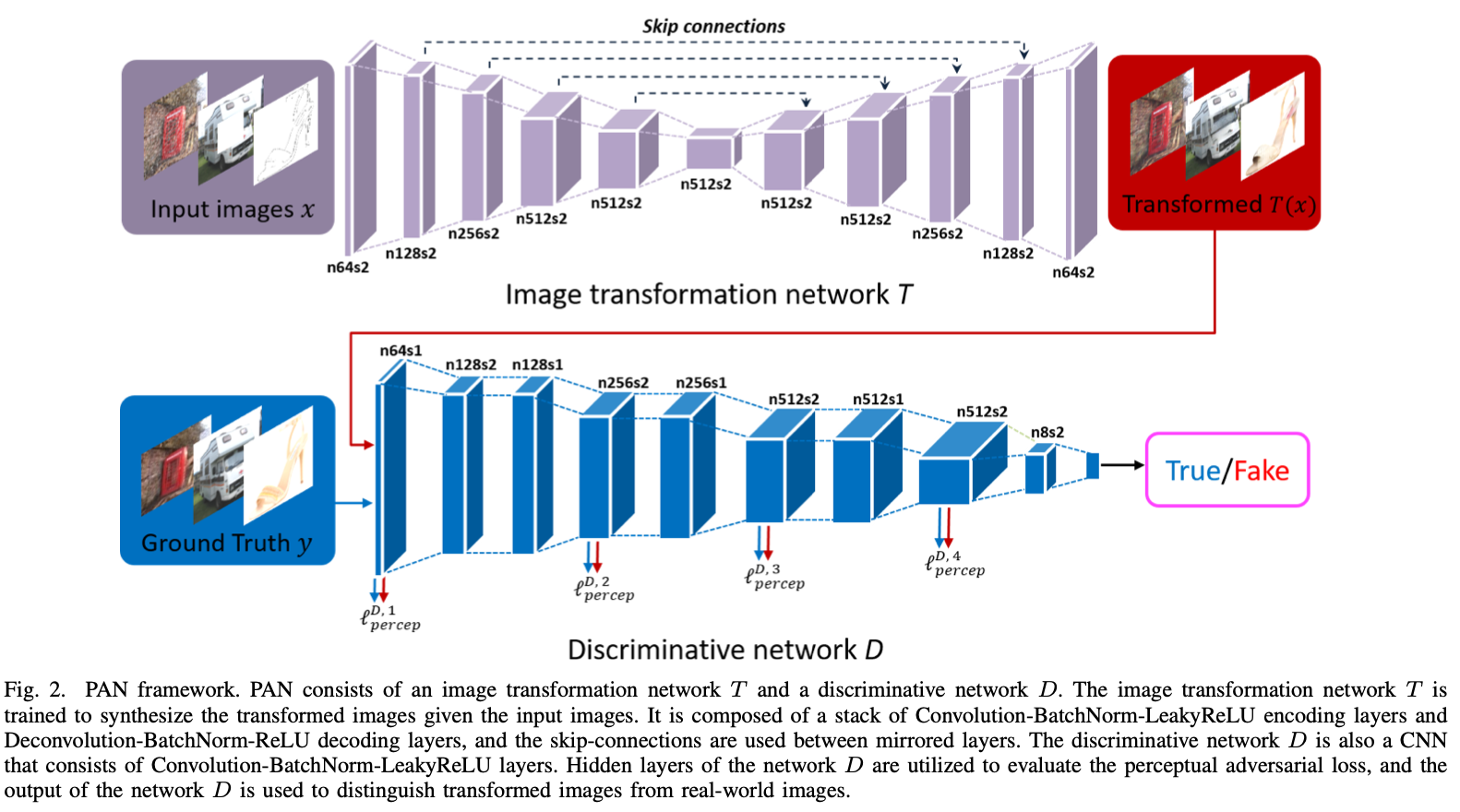
위 사진의 Image Transformation Network T는 input 이미지로부터 변환된 이미지 T(x)를 생성하기 위해서 사용되어진다. (Input 이미지 x는 각각 상응하는 Ground Truth 이미지 y를 가지고 있다.)
Generative Adversarial Learning를 성취하기 위해서는, Discrimitive Network D를 추가로 도입해야 한다. 이에 따라, Generative Adversarial Loss를 수식으로 표현하면 다음과 같다.

B. Perceptual Adversarial Loss
이 논문은 Input 이미지로부터 변환된 이미지를 추론하는 것을 목표로 삼고 있다. 따라서, GAN에서 더 나아가, Input 이미지를 ground truth로 mapping하는 과정 역시 매우 중요하다고 할 수 있다.
앞서 설명한 것과 같이, Ground-truth와 유사해지도록 이미지를 생성할 때, pixel-wise loss와 perceptual loss가 자주 사용된다. Pixel-wise loss는 pixel 공간 상에서 나타나는 discrepancy (불일치)에 벌칙을 적용시키지만, 흐릿한 결과물을 생성해낼 수 있다. Perceptual Loss는 VGG net과 같은 학습이 잘된 classifier로부터 추출된 고해상도의 이미지들 간의 불일치를 탐색한다.
Image-to-Image Transformation을 수행할 때, 숨겨진 layer로부터 feature를 추출하는 방법에 대해서 다루어지지 않았기에, 이 논문에서는 이것을 다루어 보고 있다.
이 논문에서 변환된 이미지와 Ground-truth 이미지 사이의 Perceptual Adversarial Loss를 계산하기 위해서 Discriminative Network D의 hidden layer (숨겨진 layer)들을 사용한다. 이에 대한 수식은 다음과 같다.

PAN은 Energy-Based GAN의 방식과 마찬가지로, 두 가지의 Loss를 사용한다.
하나 (LT)는 Image Transformation Network T를 학습시키기 위해 사용하고, 나머지 하나 (LD)는 Discriminative network D의 숨겨진 Layer들을 학습시키기 위해서 사용한다.
LT의 수식은 다음과 같다.

LD의 수식은 다음과 같다.

** m의 값은 지정되어 있는가 아니면 유동적인 값인가?
토의 끝에 m의 값은 연구진이 지정하는 값이라고 결론을 지었다. 실제로, 코드를 살펴보면, m = 3.0으로 두고 계산을 한 것을 확인할 수 있었다.
C. The Perceptual Adversarial Networks
앞선 A와 B에서 도출해낸 수식을 바탕으로, PAN 네트워크를 구성하게 된다. PAN은 Image Transformation network T와 Discriminative Network D로 구성되어 있다.
Image transformation network와 Discriminative network의 loss function은 다음과 같다.

여기에서, theta는 Generative adversarial loss와 perceptual adversarial loss의 영향력을 줄이기 위해서 사용하는 hyperparameter이다.
LT < m일 때, JD를 minimizing 하는 방법은 JT를 maximizing하는 것과 상응한다. LT >= m일 때, JD의 second term은 zero gradient로 구성될 것이다.
Discriminative network D는 변환된 이미지 T(x)와 Ground-truth 이미지 y를 구별하는 것을 목표로 한다. 반면에, Image Transformation network T는 output 이미지와 Ground-truth 이미지 간의 불일치를 감소시키면서 더욱 좋은 이미지를 생성하는 것을 목표로 학습된다.
D. Network Architectures
위의 fig 2.에 전체적인 구조가 나타나있다. Image Transformation network T, Discriminative network D, 총 2개의 CNN으로 구성되어 있다. 자세하게 살펴보면 다음과 같다.
1) Image Transformation network T
=> Input 이미지를 통해서 Transformed 이미지 (변환된 이미지)를 생성하기 위해서 사용되는 네트워크다.
먼저, 네트워크 T는 Convolution-BatchNorm-LeakyReLU layer 스택으로 input 이미지를 고차원의 형태로 인코딩한다. Output 이미지는 Deconvolution-BatchNorm-ReLU layer 스택으로 디코딩하면 된다. (2017년 논문이다보니, Deconvolution과 같이 outdated한 방법으로 네트워크가 구성되어 있다.)
주목해야 할 점은, 네트워크 T의 Output layer는 BatchNorm을 사용하지 않고, ReLU를 Tanh로 대체해서 사용한다. 또한, 인코더 스택과 디코더 스택을 연결하기 위해서 skip-connection이 사용된다.
구체적인 Architecture는 다음의 표와 같다.

2) Discriminative network D
=> Transformed 이미지 (변환된 이미지)와 Ground-Truth 이미지 사이의 차이를 측정하기 위해서 사용되어지는 네트워크다.
Input 이미지가 주어졌을 때, Discriminative network D는 Convolution-BatchNorm-LeakyReLU layer 스택을 활용해서 high-level feature를 추출해낸다.
1번째, 4번째, 6번째, 8번째 layer는 변환된 이미지와 Ground-truth 이미지 간의 Perceptual Adversarial Loss를 측정하기 위해서 사용되어진다. (**fig 2.의 모델을 참조하기!!!!)
마지막 convolution layer는 압축되고, 하나의 sigmoid output을 통해서 최종 output을 산출하게 되는 구조이다.
D의 output은 Input 이미지가 real-world 데이터 셋에 포함되어 있을 확률을 나타낸다.
D의 Architecture는 다음의 표와 같다.

5. Conclusion
종합적인 내용 정리는 영어로 하였다.
PAN => Generative Adversarial Loss + Perceptual Adversarial Loss
Discriminative network D => Continuously explore the discrepancy between transformed image & ground-truth image
Image Transformation T => Narrow discrepancy explored in D
2 Networks updated alternately => Through the adversarial training process


