https://arxiv.org/abs/2010.11929
International Conference on Learning Representations(ICLR) 2021
1. Introduction
이 논문은 NLP에서 Transformer의 성공에 따라, 이미지에 Transformer를 적용하는 Vision Transformer를 제안한다.
먼저, 이미지를 patch로 split하고, 해당 patch들의 linear embedding sequence를 Transformer의 input으로 넣는다. CV의 이미지 패치들은 NLP의 token과 거의 유사하게 사용된다.
강하게 Regularization을 하지 않고, ImageNet과 같이 중간 크기의 데이터셋에 학습을 시킬 때, ResNet보다 정확도가 살짝 낮게 나왔다. 하지만, 큰 크기의 데이터셋에서 학습을 시킬 때 대규모 차원의 학습이 귀납적 편향을 해소해준다는 것을 확인할 수 있었다고 한다. 그리고 논문은 ViT가 충분하게 pre-train이 되고, 적은 데이터포인트를 가진 과제에 적용이 되면 더욱 좋은 결과를 나타낸다고 한다.
3. Method

전체 모델의 Architecture는 위와 같다.
먼저, 이미지 x를 flatten된 2차원 패치로 reshape하게 된다. Transformer는 일정한 latent vector D를 모든 레이어에 걸쳐서 사용하게 돼서 논문에서는 patch들을 flatten시키고 D차원으로 매핑시키게 되는데, ViT에서는 BERT의 Class 토큰과 유사하게, 패치 임베딩의 맨 앞에 학습가능한 임베딩을 붙이게 된다. 이 임베딩을 Transformer Encoder를 통과시켜서 나오게 되는 output인 y가 이미지 표현 역할을 수행하게 된다.
Classification head는 MLP에 의해서 수행되며, pre-train 단계에서는 one-hidden layer, fine-tuning 단계에서는 single linear layer로 수행된다.
또한, 위치 정보를 유지시키기 위해서 위치 임베딩이 패치 임베딩에 추가되었는데, 이 때 학습가능한 1차원 위치 임베딩을 사용하였다. 2차원 임베딩은 성능 향상이 크게 나타나지 않았기 때문에, 이 논문에서는 1차원만 사용하였다.
최종적으로 생성된 임베딩 벡터 시퀀스는 인코더의 input으로 사용되게 된다.
Transformer Encoder


트랜스포머 인코더는 multiheaded self-attention과 MLP 블록으로 구성되어 있다. Layernorm이 블록 앞에 적용됐고, residual connection은 블록 뒤에 각각 적용되어 있다. 그리고, MLP는 GELU Activation Function을 사용한 레이어 2개를 포함하고 있다.
Inductive Bias
Inductive Bias는 학습시에 만나보지 못한 상황에 대해서 정확하게 예측을 하기 위해서 사용이 되어지는 추가적인 가정을 의미하는데, 논문에서 의하면 ViT가 CNN보다 inductive bias가 부족하다.
CNN에서는 locality, 2차원 neighborhood structure, translation equivariance가 모델 전반적으로 사용이 되는 반면에, ViT는 MLP 레이어만 local하고 translationally equivariant하고 self-attention은 local하지 않고 global하다는 특성을 가진다.
이에 따라, ViT에서는 패치의 모든 공간 관계는 처음부터 학습을 해야한다는 특징이 있다.
Hybrid Architecture
보통 이미지 패치를 그냥 사용하는 것 대신에 input sequence에서 CNN feature map을 사용할 수 있다.
이 논문의 Hybrid Architecture에서 patch embedding projection E는 CNN feature map으로부터 뽑아낸 패치들에 적용되게 된다.
4. Experiments
4.1 Setup
Datasets
- ILSVRC-2012 ImageNet, 1K classes, 1.3M images
- ImageNet-21K, 21K classes, 14M images
- JFT, 18K classes, 303M images
Transfer Learning Datasets
- ImageNet
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102

다음으로 Model Variant에 대해서 소개해자면, BERT에서 사용한 설정을 기본으로 해서 실험을 진행했다. Base와 Large는 BERT의 모델로부터 직접 가지고 왔고, Huge만 따로 저자들이 추가했다.
Training은 Adam Optimizer를 사용했고, 베타1은 0.9, 베타2는 0.999로 두고 batchsize = 4096, weight decay = 0.1로 두고 실험을 진행했다.
Fine-tuning은 momentum이 있는 SGD를 사용해서 진행을 했고, few-shot 또는 fine-tuning accuracy를 통해서 downstream dataset에 대한 결과값을 산출하였다.
4.2 Comparison to State-Of-The-Art (SOTA)

Vit-H/14 가 기존의 모델들에 비해서 월등히 좋은 성능을 가지고 있다는 것을 확인할 수 있고, 오른쪽 아래의 그래프들을 보면, ViT-H/14가 모든 task에서 가장 뛰어난 정확도를 가지고 있음을 확인할 수 있다.
4.3 Pre-Training Data Requirements
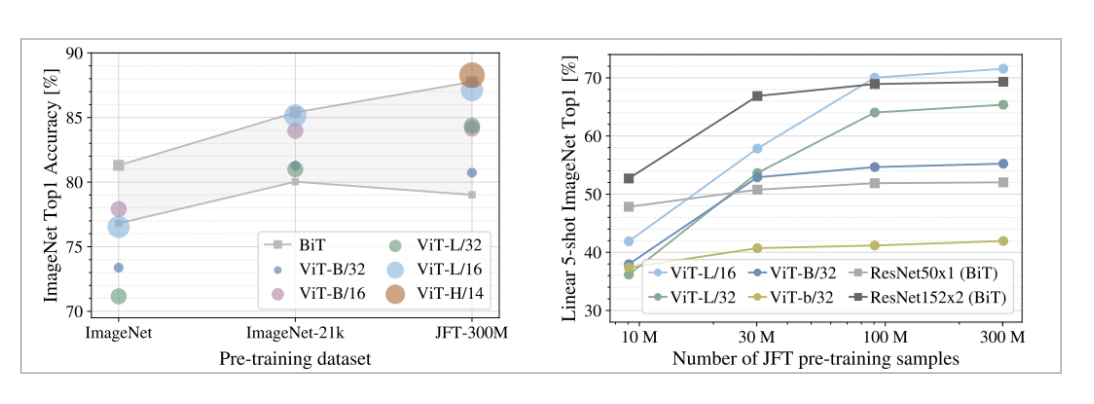
앞서, 인트로에서 ViT가 중간 사이즈의 데이터셋에서 정확도가 비교적 낮다고 언급하였는데, 위의 그래프가 해당 정확도를 나타내었다. 또한, 오른쪽의 JFT 데이터셋에 학습을 시켰을 때, sample의 개수가 증가할 수록 정확도가 점점 개선되면서 성능이 올라가고 있는 것을 확인할 수 있다.
정리하자면, 데이터셋의 크기에 따른 성능 차이가 존재한다고 할 수 있다.
4.4 Scaling Study
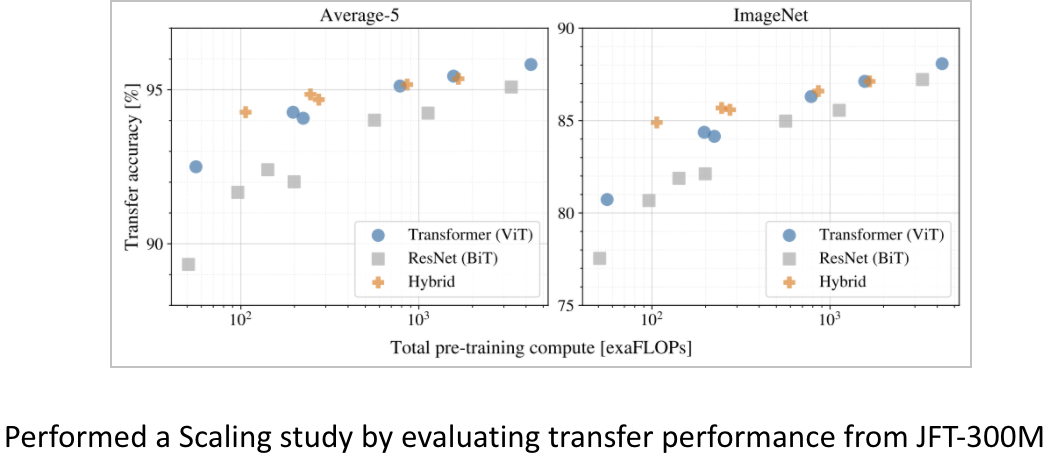
이 논문에서는 JFT-300M으로부터 전이학습 성능을 확인하기 위해서 여러 모델에 대한 Scaling Study를 진행했는데, 위의 그래프에서 몇가지 특징을 정리할 수 있다.
먼저, ViT의 성능/계산량 트레이드오프는 ResNet보다 훨씬 좋다.
두번째로, 모델이 커질수록 Hybrid과 ViT의 차이가 사라졌다.
마지막으로, ViT는 saturate되지 않고, 추가적인 scaling이 가능하다.
5. Conclusion
이 논문에서는 image를 여러개의 패치로 나누고, NLP에서 사용하는 기본적인 Transformer encoder를 통해서 Image Classification을 진행하였다. 놀랍게도 큰 크기의 데이터셋에 적용을 했을 때 기존의 CNN 계열보다 성능이 좋은 것을 확인할 수 있었지만, 논문에서는 추후에 연구해야 할 부분이 크게 3가지가 있다고 보았다.
첫째, ViT를 Classification이외의 다른 비전 문제에 적용해야 하고, 두번째로 self-supervised pre-training method에 대해서 연구를 해야하고, 마지막으로 ViT의 scaling을 더 진행시켜서 성능 개선을 하는 연구를 해야 할 것을 제안하였다.
'AI 논문 정리 > Attention & Transformers' 카테고리의 다른 글
| [Paper Review 2] Deep ViT: Towards Deeper Vision Transformer (0) | 2022.05.17 |
|---|
