https://arxiv.org/abs/2103.11886
1. Introduction
Convolution layer를 몇 개씩 쌓아 올려서 global information을 모아놓는 CNN과 다르게, ViT는 self-attention 메커니즘을 사용하여 layer-wise local feature extraction을 하지 않고도 global information을 모을 수 있다. 이러한 과정을 거쳐, ViT의 성능은 CNN보다 좋다고 할 수 있다.
최근 CNN 연구에 있어, deep model을 학습시키는 과정이 주가 되었기 때문에, 저자들은 "ViT 또한 CNN과 비슷하게 deep하게 만들어서 성능을 개선시킬 수 있지 않을까?"라는 의문을 가지게 되었다. ViT는 self-attention 메커니즘이 주가 되기 때문에, 이 질문에 대한 답을 내리기 어려울 수 있는데, 저자들은 답을 내리기 위해서, ViT의 Depth와 Scalability에 대한 연구를 진행하였다.
ViT의 depth가 깊어질수록, 몇 개의 Layer를 지나고서부터 Attention map이 대체로 비슷하다는 특징이 있었다. 이에 따라, representation이 몇 개의 Layer를 지나고 나서부터 개선되지 않는 현상이 발생했는데, 논문에서는 이를 Attention Collapse라고 명명했다. 정리하자면, ViT가 깊어지면 깊어질수록 self-attention 메커니즘이 더 이상 효과적이지 않다는 것이다.
이를 해결하기 위해, 논문에서는 새로운 self-attention 메커니즘인 Re-attention을 소개한다. Re-attention은 multi-head self-attention 구조를 사용하고 있고, 다른 attention head로부터 정보를 교환하는 방법으로 attention map을 다시 생성한다.
논문의 contribution을 정리하면, 다음과 같다.
1. Vision Transformer의 행동을 심도있게 분석하고, CNN처럼 layer를 더 쌓는 방법으로는 성능 개선을 하지 못한다는 점을 발견하였다. 이러한 현상의 원인을 Attention collapse라고 규정지었다.
2. Re-attention을 소개하였다.
3. 최초로 ImageNet-1k에 32-block ViT를 성공적으로 학습시켰다. Self-attention을 Re-attention으로 대체하는 것으로 SOTA 달성을 할 수 있었다.
3. Revisiting Vision Transformer

Deep ViT와 ViT의 차이점은 Attention에 있다는 것을 확인할 수 있다.
3.1 Multi-Head Self-Attention
지난번에 정리한 ViT에 대해서 간략하게 설명하는 파트다. 특히, ViT의 multi-head self-attention (MHSA) layer와 feed-forward multi-layer perceptron (MLP)에 대해 소개를 한다.
MHSA는 학습가능한 associate memory를 생성해내는데, 각각의 memory는 query (Q), pair of key (K) - value (V) pair를 갖고 있다. 수학적으로 표현하면 다음 수식과 같다.
루트 (d)는 네트워크의 depth를 기반으로 하는 scaling vector이다.
3.2 Attention Collapse
앞서 언급한 것과 같이, ViT는 깊어진다고 해서 성능이 더 좋아지는 것이 아니다. 이 논문에서는 self-attention 메커니즘이 그 이유라고 생각을 하고, 모델이 깊어질 때 attention map에 대해서 분석을 하였다.
위의 수식으로 attention map간의 cross-layer similarity를 계산하였다. A∗ h,:,t는 token t가 T output token에 얼마나 기여를 하는 지 나타내는 T-dimensional 벡터이다.
위의 figure를 보면, 17번째 블럭 이후, similar attention map은 90%에 달한다. 이는, Attention map은 뒤로 갈수록 서로 유사하고, Transformer block이 MLP로 degenerate될 수 있다고 나타낸다.
Attention collapse가 ViT model performace를 얼마나 저해할 수 있는지 알아보기 위해서, 저자들은 cosine similarity를 통해서 final output features와 intermediate transformer block의 output을 비교하였다.
위 그래프를 보면 20번째 블럭부터는 feature들의 성능 향상이 멈추게 된다는 것을 확인할 수 있다. 즉, attention collapse는 ViT의 non-scalable issue의 원인이라고 규정할 수 있다.
4. Re-attention for Deep ViT
앞서 언급한 것과 같이, Attention Collapse 문제가 Deep ViT의 가장 큰 장애물 중 하나라고 할 수 있다. 이 파트에서는 attention collapse를 해결하기 위한 방안 2가지를 다룰 예정이다.
4.1 Self-Attention in Higher Dimension Space
첫번째는 각각의 token의 embedding dimension을 늘리는 방법이다. 이렇게 되면, 각각의 token에 인코딩할 정보가 더 많아진다. 그 결과로, attention map들이 더욱 다채로워질 수 있으며, attention map similarity 또한 줄어들 수 있다.
논문에서는 12 block의 ViT로 실험을 진행하였다. 256-758 range의 embedding dimension이 선택되었다.
위의 결과에서 볼 수 있듯이, Attention map similarity가 줄었다는 것을 확인할 수 있으며, embedding dimension이 커지면 accuracy도 좋아진다는 것을 확인할 수 있다.
하지만, embedding dimension을 증가시키면, computation cost가 증가하고, 큰 모델을 사용할 때, overfitting risk와 성능 저하가 발생할 수 있다는 문제점이 있다.
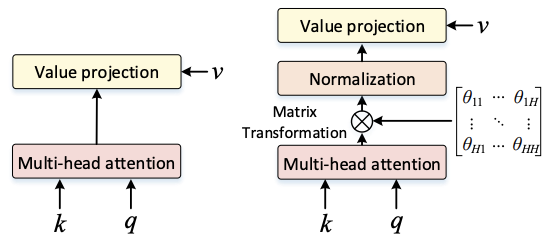
4.2 Re-Attention
앞서 계속해서 말한 것과 같이, 다른 transformer block의 attention map들의 similarity가 높다. 하지만, 같은 transformer block의 다른 head에서 도출된 attention map의 similarity는 상당히 낮은 편이다. 이는, 같은 self-attention layer여도, 각각 다른 head는 input token의 각각 다른 요소에 주목하기 때문이다.
따라서, 논문 저자들은 cross-head communication을 통한 attention map regeneration을 하여 ViT의 성능을 개선시키고자 한다.
Re-Attention의 수식은 다음과 같다.
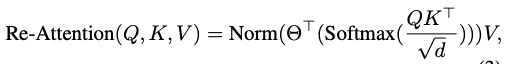
Norm은 layer-wise variance를 줄이기 위해서 사용한 normalization function이며, theta는 end-to-end learnable하다는 특징이 있다. (end-to-end learnable이란? input과 ouput 사이의 단계를 모두 학습할 수 있다는 것을 의미한다)
Re-Attention의 장점
1. Re-attention은 제각기 다른 attention head 사이의 interaction을 탐색하여, attention map diversity를 높이는 데 일조한다.
2. Re-attention은 효과적이고, 구현하기 쉽다. (self-attention에 비해 코드가 짧고, computational overhead가 작다)
-> 첫번째 방법이었던 embedding dimension increase보다 훨씬 효율이 좋음
5. Experiments
5.1 Experiment Details
AdamW Optimizer와 Cosine learning rate decay policy (learning rate = 0.0005)를 사용하였다. 8 Tesla-V100 GPU와 300 epoch롤 학습을 시켰고, batch size는 256이었다.
모든 실험에서 이미지 사이즈는 224 X 224이었으며, 모든 MLP layer의 embedding dimension은 384, expansion ratio는 3으로 지정되었다.
5.3 Analysis on Re-attention
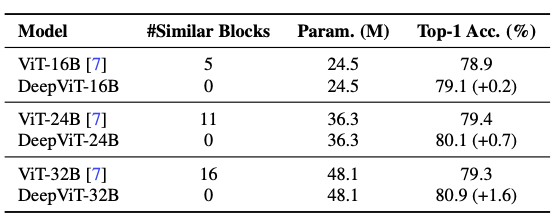
위의 표에서 볼 수 있듯이, Re-attention을 적용한 Deep ViT를 사용할 때, Similar Blocks의 값이 0인 것을 확인할 수 있다. 즉, Re-attention은 Attention collapse 문제를 해결할 수 있다.
6. Conclusion
1. ViT가 깊어지면 깊어질 수록 Attention Collapse 문제가 발생한다.
2. Re-attention을 통해서 attention collapse를 해결할 수 있다.
